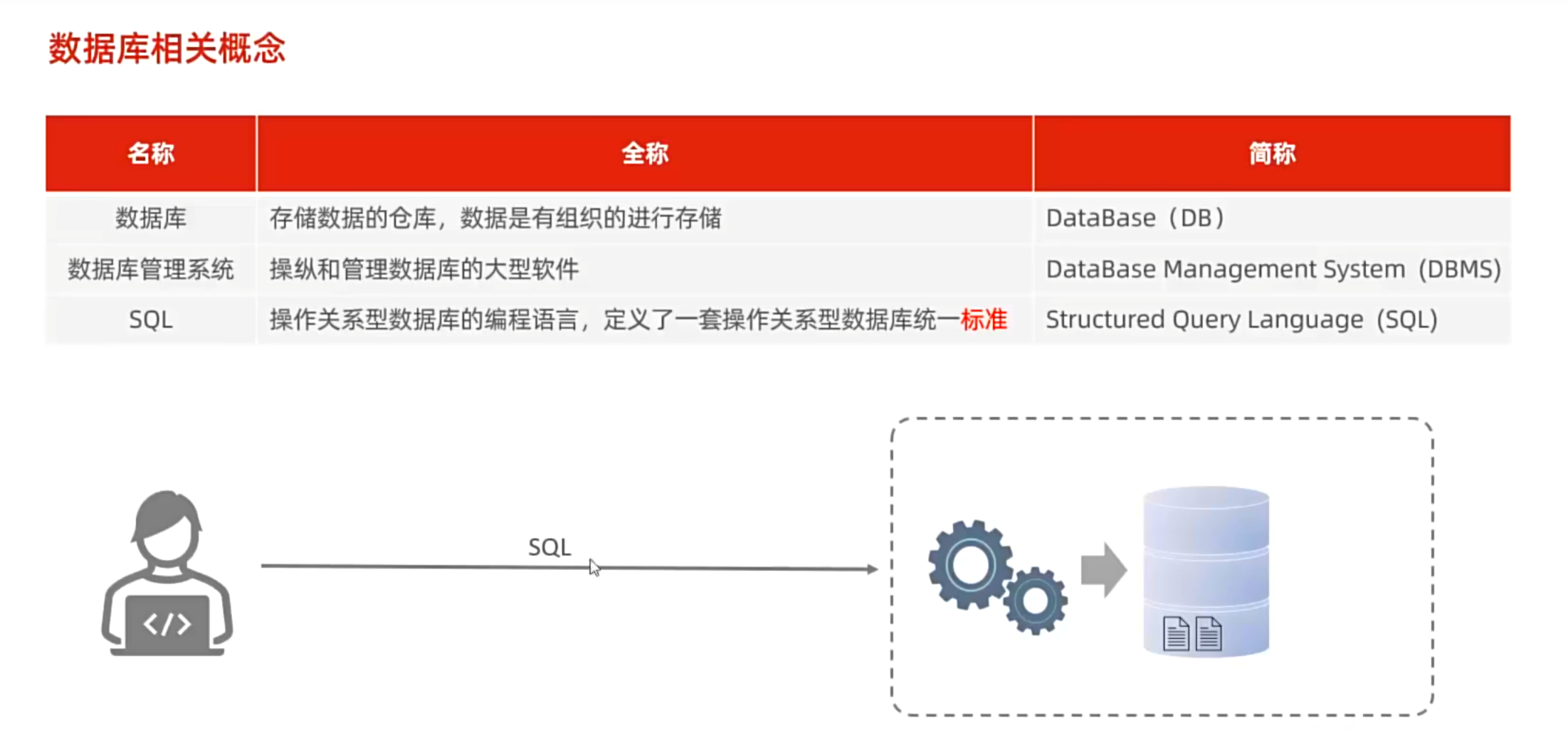
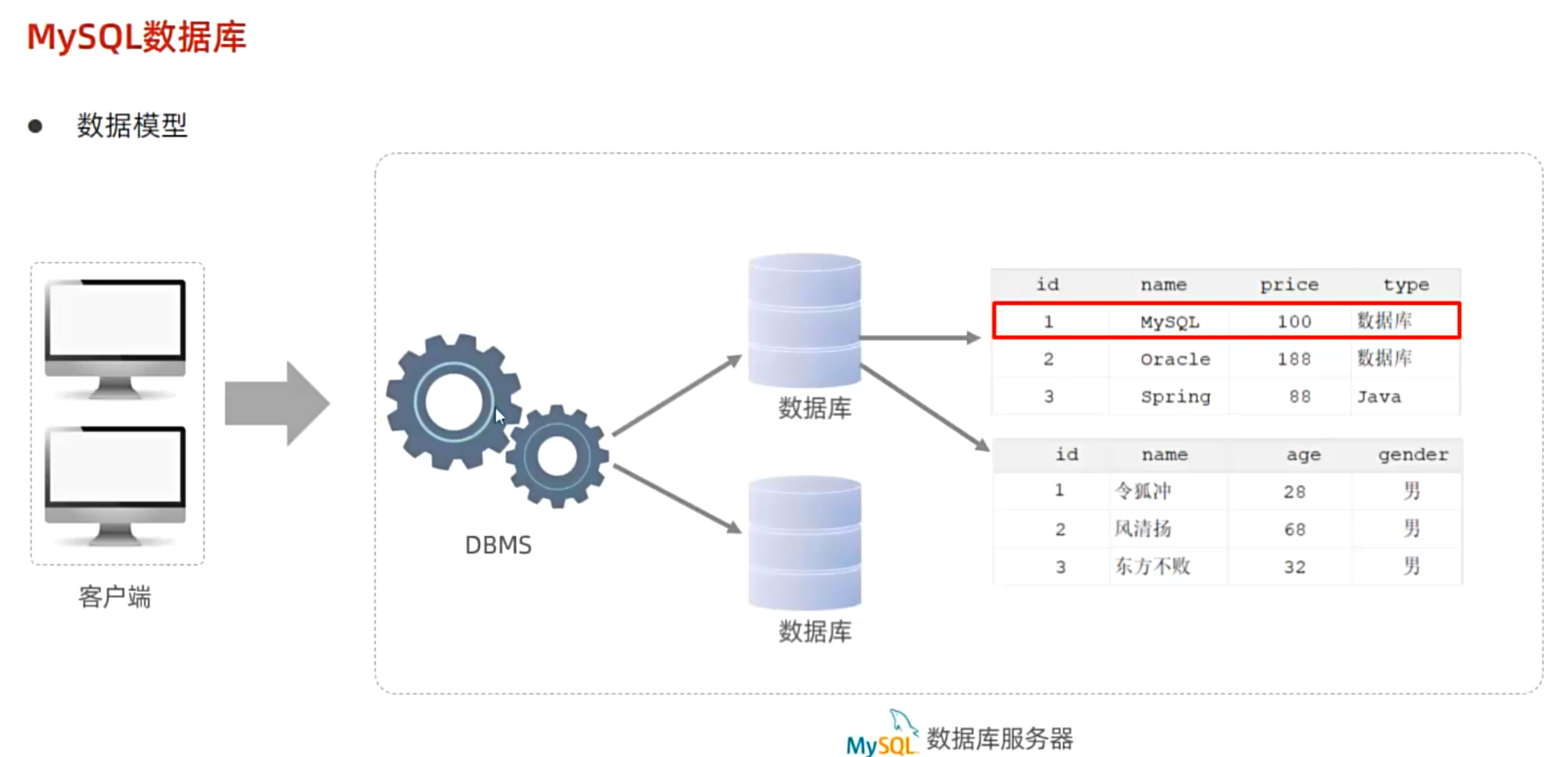
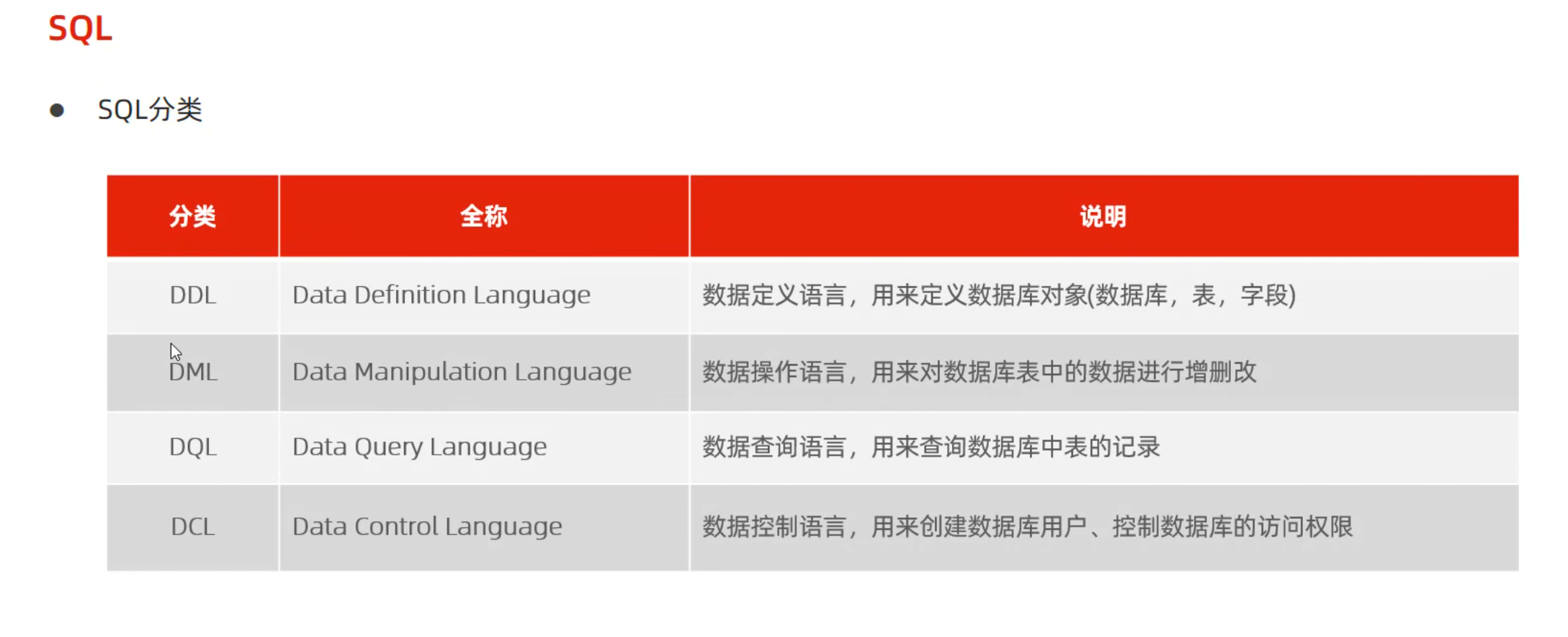
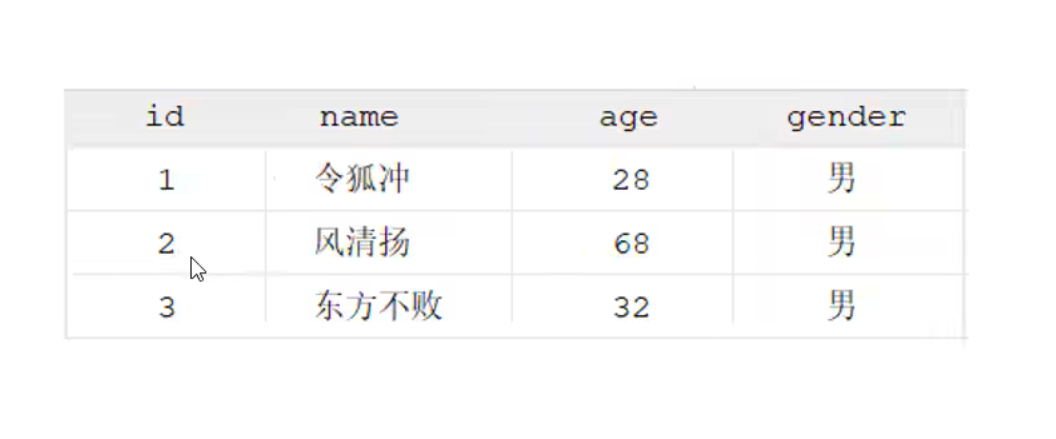
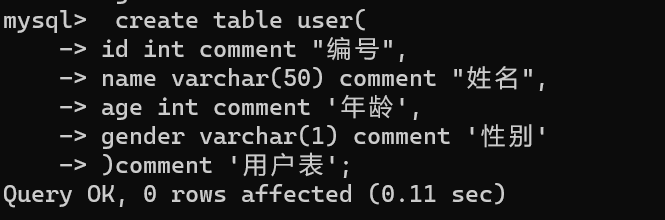
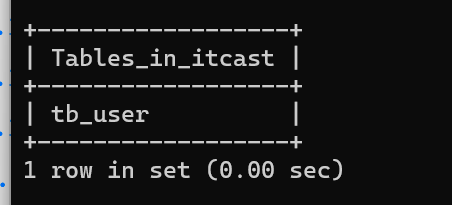
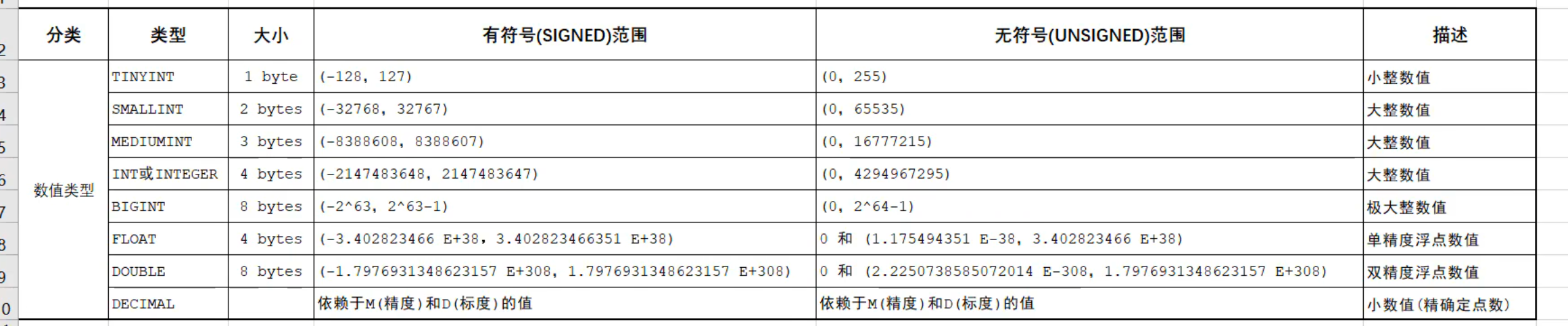
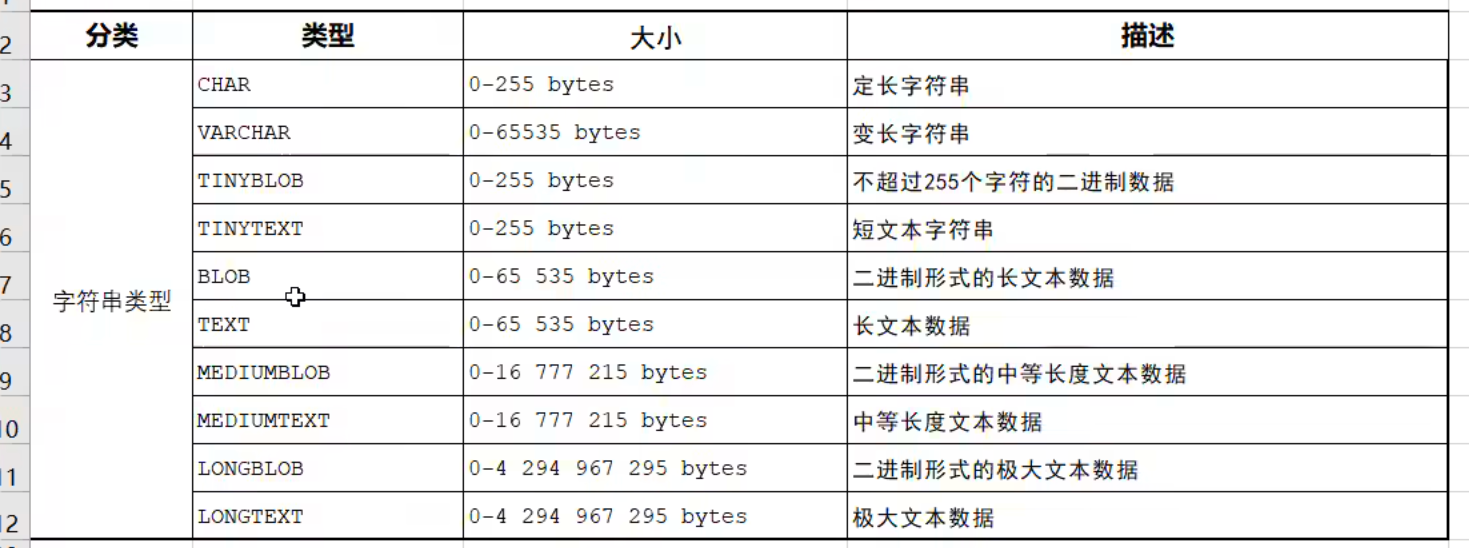
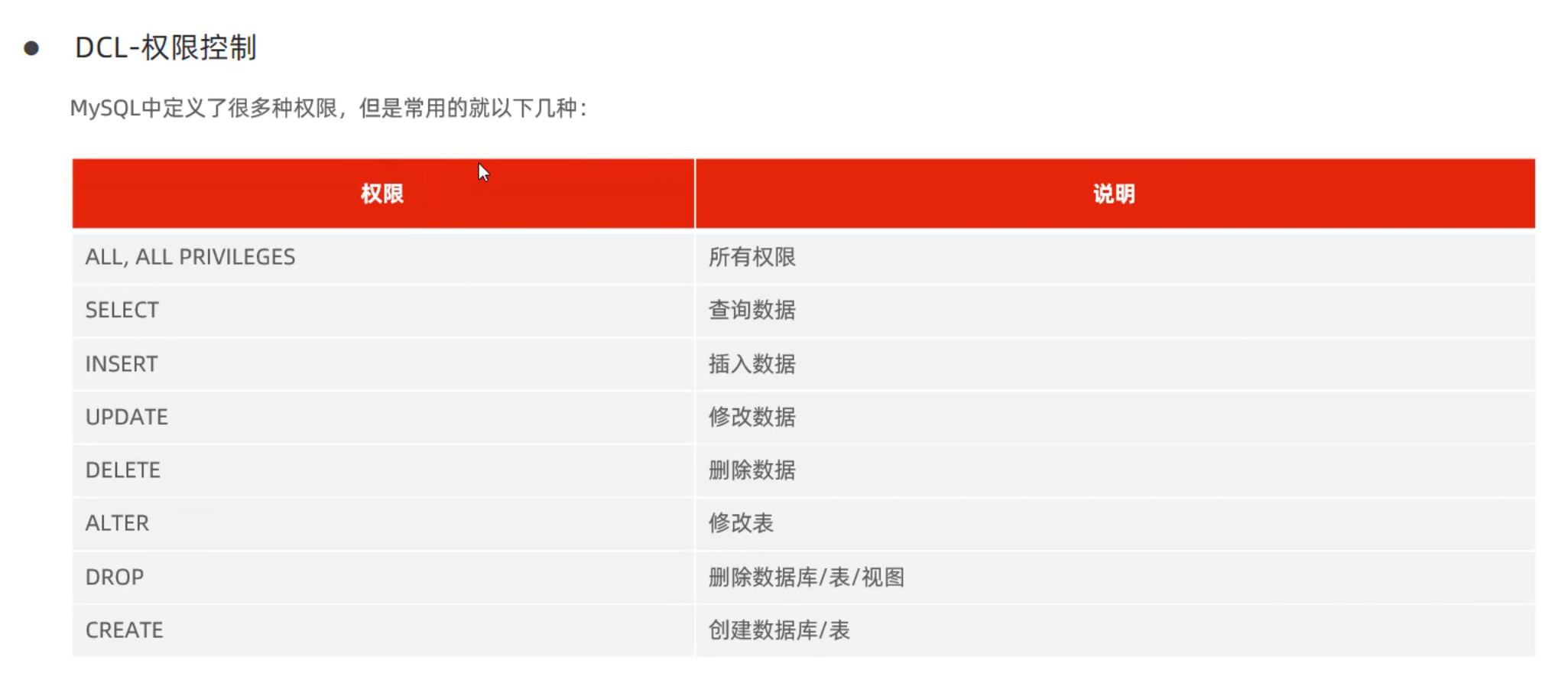
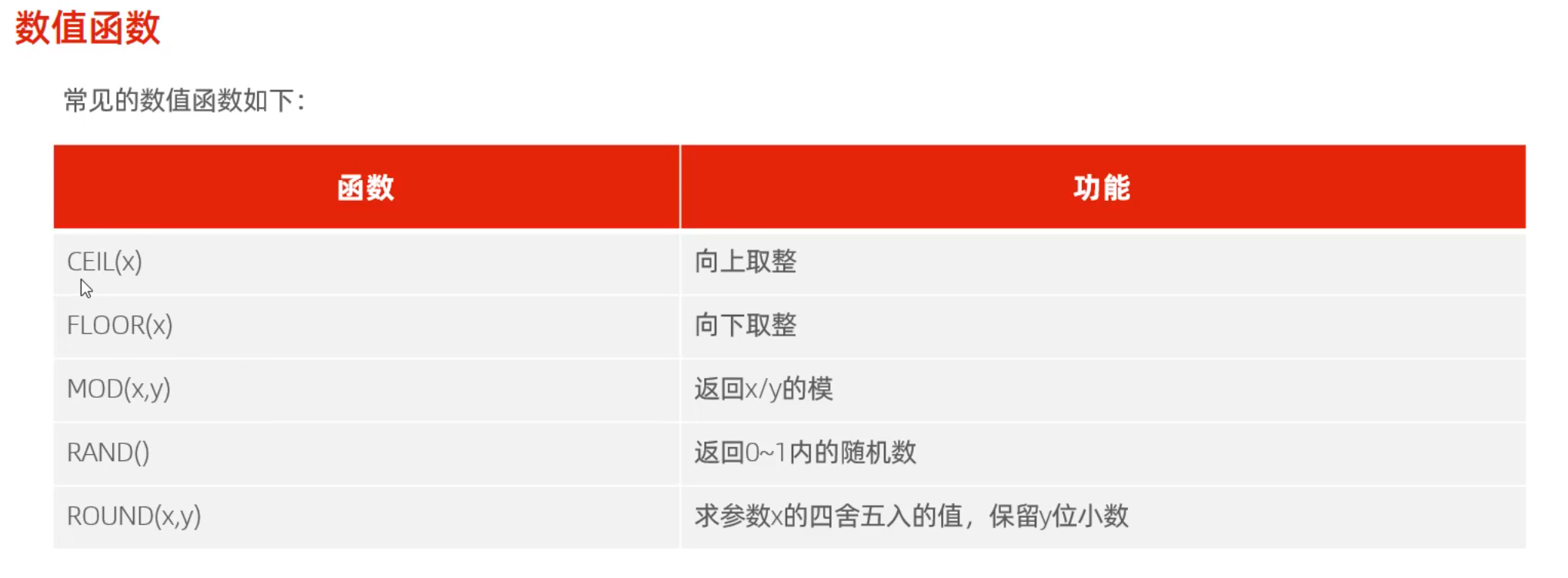
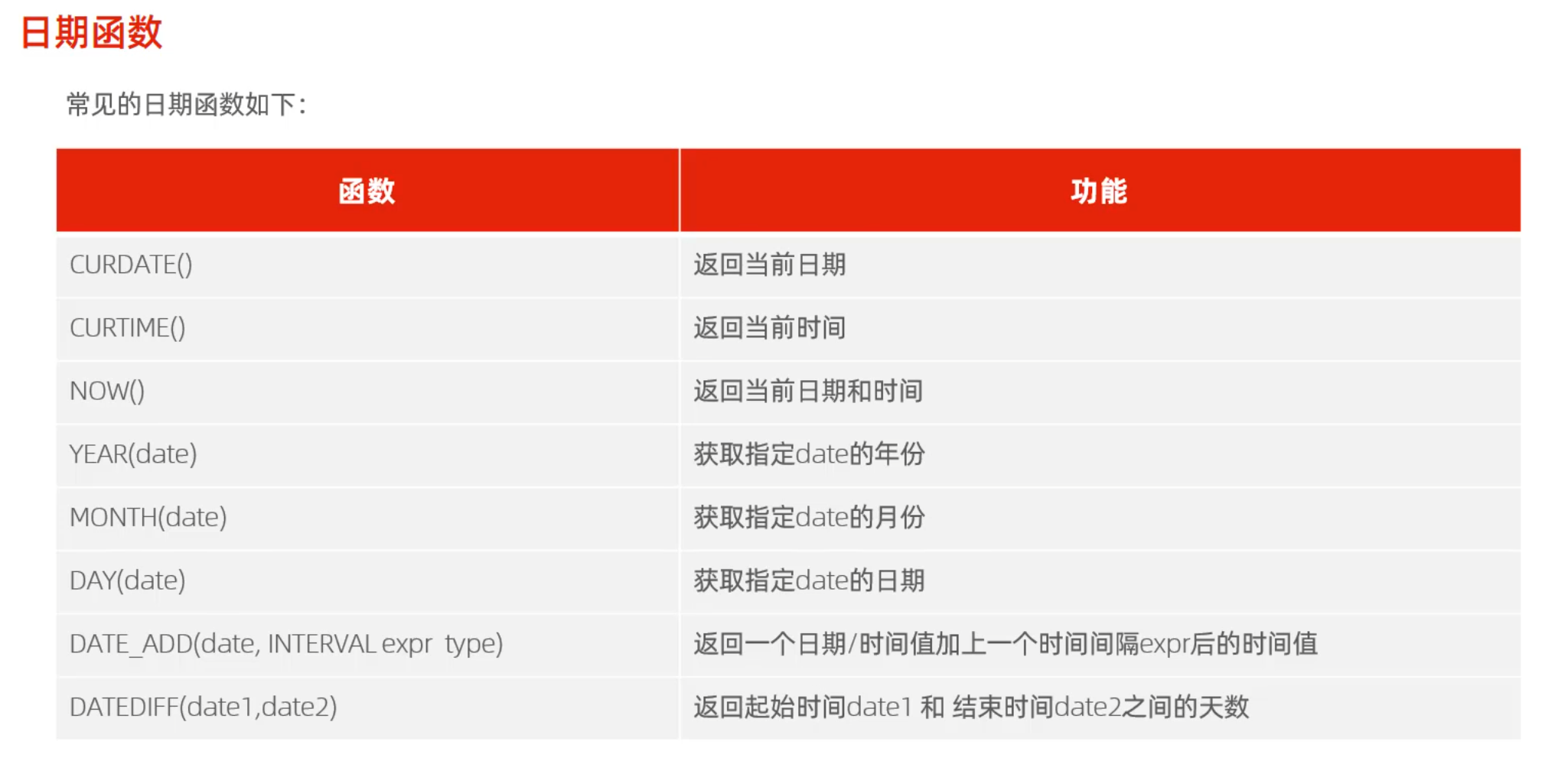
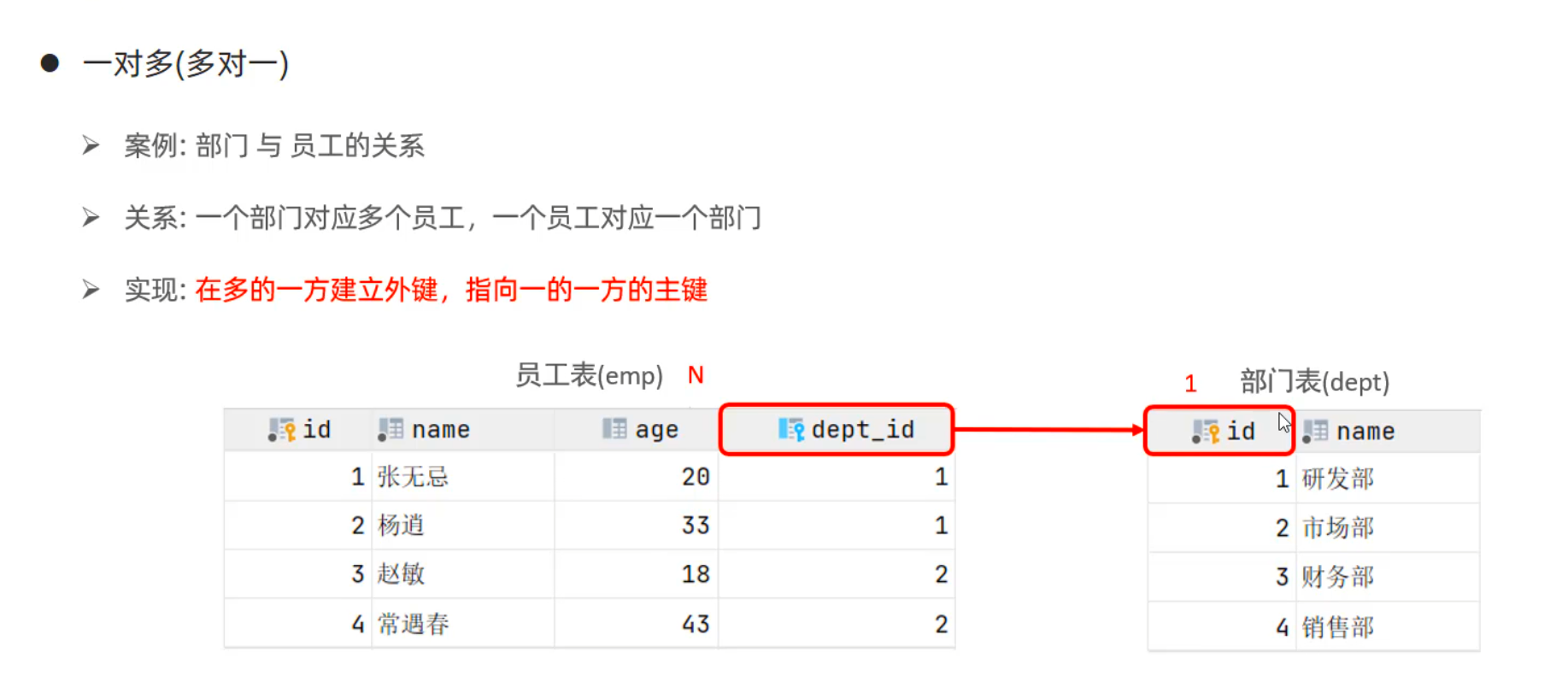
显式内连接 SELECT 字段列表 FROM 表1 [INNER] JOIN 表2ON 连接条件 ...;
注意:内连接查询的是两张表交集的部分
例子:
1 2 3 4 5
-- 查询员工姓名,及关联的部门的名称 -- 隐式 select e.name, d.name from employee as e, dept as d where e.dept = d.id; -- 显式 select e.name, d.name from employee as e innerjoin dept as d on e.dept = d.id;
-- 左 selecte.*, d.name from employee eleftouterjoin dept d one.dept = d.id; select d.name, e.* from dept d leftouterjoin emp eone.dept = d.id; -- 这条语句与下面的语句效果一样
-- 右 select d.name, e.* from employee erightouterjoin dept d one.dept = d.id;
连接查询-自连接
自连接查询语法:
自连接查询,可以是内连接查询,也可以是外连接查询。
1
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...;
注意:在自连接查询时必须取别名
例子:
1 2 3 4
-- 查询员工及其所属领导的名字 select a.name, b.name from employee a, employee b where a.manager = b.id; -- 没有领导的也查询出来 select a.name, b.name from employee a left join employee b on a.manager = b.id;
联合查询-union,union all
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
语法:
1 2 3
SELECT 字段列表 FROM 表A ... UNION [ALL] SELECT 字段列表 FROM 表B ...;
注意事项
union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致
子查询
概念:SQL语句中嵌套SELECT语句,称谓嵌套查询,又称子查询。
1
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
子查询外部的语句可以是INSERT/UPDATE/DELETE/SELECT的任何一个。
根据子查询结果不同,分为:
标量子查询(子查询结果为单个值)
列子查询(子查询结果为一列)
行子查询(子查询结果为一行)
表子查询(子查询结果为多行多列)
根据子查询位置,分为:WHERE之后、FROM之后、SELECT之后。
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询成为标量子查询。
常用的操作符:= <> > >= < <=
例子:
1 2 3 4 5 6 7 8 9
-- 查询销售部所有员工 select id from dept wherename = '销售部'; -- 根据销售部部门ID,查询员工信息 select * from employee where dept = 4; -- 合并(子查询) select * from employee where dept = (select id from dept wherename = '销售部');
-- 查询xxx入职之后的员工信息 select * from employee where entrydate > (select entrydate from employee wherename = 'xxx');
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
例子:
1 2 3 4 5 6 7 8
-- 查询销售部和市场部的所有员工信息 select * from employee where dept in (select id from dept wherename = '销售部'orname = '市场部');
-- 查询比财务部所有人工资都高的员工信息 select * from employee where salary > all(select salary from employee where dept = (select id from dept wherename = '财务部'));
-- 查询比研发部任意一人工资高的员工信息 select * from employee where salary > any (select salary from employee where dept = (select id from dept wherename = '研发部'));
行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:=、<>、IN、NOT、IN
例子:
1 2 3
-- 查询与xxx的薪资及直属领导相同的员工信息 select * from employee where (salary, manager) = (12500, 1); select * from employee where (salary, manager) = (select salary, manager from employee wherename = 'xxx');
表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
例子:
1 2 3 4
-- 查询与xxx1,xxx2的职位和薪资相同的员工 select * from employee where (job, salary) in (select job, salary from employee where name = 'xxx1'or name = 'xxx2'); -- 查询入职日期是2006-01-01之后的员工,及其部门信息 selecte.*, d.* from (select * from employee where entrydate > '2006-01-01') aseleftjoin dept as d one.dept = d.id;